并发爬虫
并发是指在一台处理器上“同时”处理多个任务。并发是在同一实体上的多个事件。强调多个事件在同一时间间隔发生。
进程、线程以及协程
进程概念
计算机的核心是CPU,承担了所有的计算任务;而操作系统是计算机的管理者,它负责任务的调度、资源的分配和管理,安排所有计算机硬件;应用程序则是具有某种功能的程序,程序是运行于操作系统之上的。
进程是一个具有一定独立功能的程序在一个数据集上的一次动态执行的过程,是操作系统进行资源分配和调度的一个独立单位,是应用程序运行的载体。
多道技术:空间复用+时间复用,于是有了进程!
进程状态反映进程执行过程的变化。这些状态随着进程的执行和外界条件的变化而转换。在三态模型中,进程状态分为三个基本状态,即运行态,就绪态,阻塞态。在五态模型中,进程分为新建态、终止态,运行态,就绪态,阻塞态。

线程的概念
早期的操作系统中并没有线程的概念,进程是能拥有资源和独立运行的最小单位,也是程序执行的最小单位。任务调度采用的是时间片轮转的抢占式调度方式,而进程是任务调度的最小单位,每个进程有各自独立的一块内存,使得各个进程之间内存地址相互隔离。后来,随着计算机的发展,对CPU的要求越来越高,进程之间的切换开销较大,已经无法满足越来越复杂的程序的要求了。于是就发明了线程。
线程是程序执行中一个单一的顺序控制流程,是程序执行流的最小单元,是处理器调度和分派的基本单位。
一个进程可以有一个或多个线程,各个线程之间共享程序的内存空间(也就是所在进程的内存空间)。一个标准的线程由线程ID、当前指令指针(PC)、寄存器和堆栈组成。而进程由内存空间(代码、数据、进程空间、打开的文件)和一个或多个线程组成。
当线程的数量小于处理器的数量时,线程的并发是真正的并发,不同的线程运行在不同的处理器上。但当线程的数量大于处理器的数量时,线程的并发会受到一些阻碍,此时并不是真正的并发,因为此时至少有一个处理器会运行多个线程。
在单个处理器运行多个线程时,并发是一种模拟出来的状态。操作系统采用时间片轮转的方式轮流执行每一个线程。现在,几乎所有的现代操作系统采用的都是时间片轮转的抢占式调度方式,如我们熟悉的Unix、Linux、Windows及macOS等流行的操作系统。
我们知道线程是程序执行的最小单位,也是任务执行的最小单位。在早期只有进程的操作系统中,进程有五种状态,创建、就绪、运行、阻塞(等待)、退出。早期的进程相当于现在的只有单个线程的进程,那么现在的多线程也有五种状态,现在的多线程的生命周期与早期进程的生命周期类似。
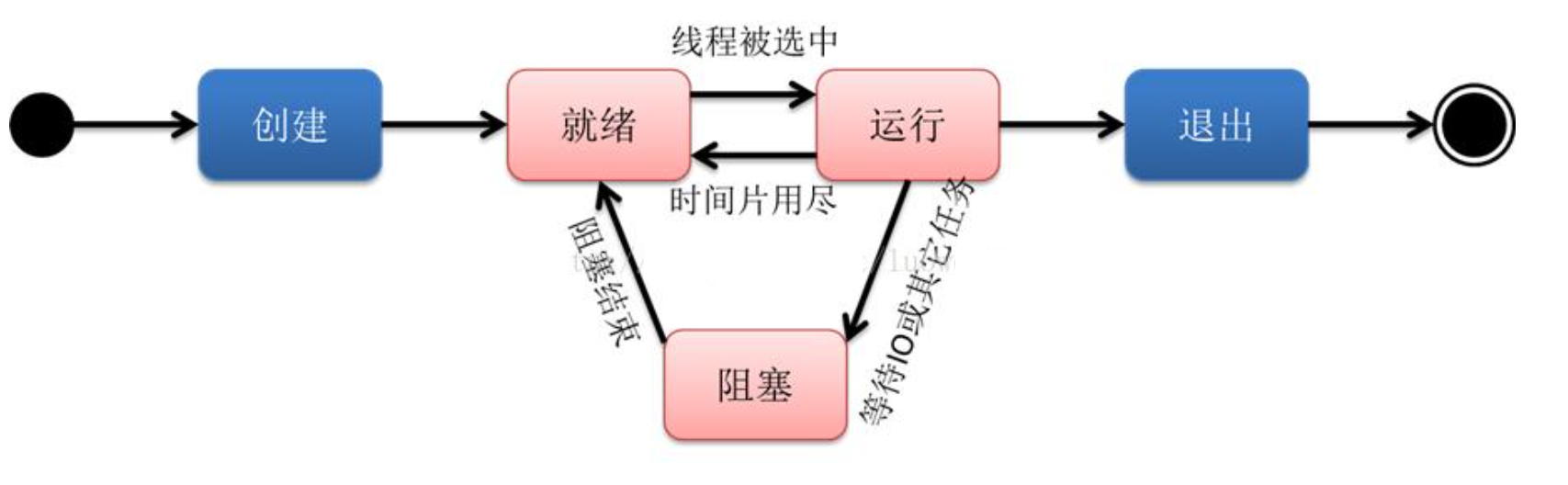
线程的生命周期
创建:一个新的线程被创建,等待该线程被调用执行;
就绪:时间片已用完,此线程被强制暂停,等待下一个属于它的时间片到来;
运行:此线程正在执行,正在占用时间片;
阻塞:也叫等待状态,等待某一事件(如IO或另一个线程)执行完;
退出:一个线程完成任务或者其他终止条件发生,该线程终止进入退出状态,退出状态释放该线程所分配的资源。
- 线程是程序执行的最小单位,而进程是操作系统分配资源的最小单位;
- 一个进程由一个或多个线程组成,线程是一个进程中代码的不同执行路线;
- 进程之间相互独立,但同一进程下的各个线程之间共享程序的内存空间(包括代码段、数据集、堆等)及一些进程级的资源(如打开文件和信号),某进程内的线程在其它进程不可见;
- 调度和切换:线程上下文切换比进程上下文切换要快得多。
协程
协程(Co-routine),也可称为微线程,或非抢占式的多任务子例程,一种用户态的上下文切换技术(通过一个线程实现代码块间的相互切换执行)。这种由程序员自己写程序来管理的轻量级线程叫做用户空间线程,具有对内核来说不可见的特性。正如一个进程可以拥有多个线程一样,一个线程也可以拥有多个协程。
协程解决的是线程的切换和内存开销的问题
- 用户空间 首先是在用户空间, 避免内核态和用户态的切换导致的成本。
- 由语言或者框架层调度
- 更小的栈空间允许创建大量实例(百万级别)
多线程
threading模块
- Python提供两个模块进行多线程的操作,分别是
thread和threading,前者是比较低级的模块,用于更底层的操作,一般应用级别的开发不常用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| import time
def foo():
print("foo start...")
time.sleep(5)
print("foo end...")
def bar():
print("bar start...")
time.sleep(3)
print("bar end...")
import threading
start = time.time()
t1 = threading.Thread(target=foo, args=())
t1.start()
t2 = threading.Thread(target=bar, args=())
t2.start()
end = time.time()
print(end - start)
|
互斥锁
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| import time
import threading
Lock = threading.Lock()
def addNum():
global num
Lock.acquire()
t = num - 1
time.sleep(0.0001)
num = t
Lock.release()
num = 100
thread_list = []
for i in range(100):
t = threading.Thread(target=addNum)
t.start()
thread_list.append(t)
for t in thread_list:
t.join()
print('Result: ', num)
|
线程池
系统启动一个新线程的成本是比较高的,因为它涉及与操作系统的交互。在这种情形下,使用线程池可以很好地提升性能,尤其是当程序中需要创建大量生存期很短暂的线程时,更应该考虑使用线程池。
线程池在系统启动时即创建大量空闲的线程,程序只要将一个函数提交给线程池,线程池就会启动一个空闲的线程来执行它。当该函数执行结束后,该线程并不会死亡,而是再次返回到线程池中变成空闲状态,等待执行下一个函数。
此外,使用线程池可以有效地控制系统中并发线程的数量。当系统中包含有大量的并发线程时,会导致系统性能急剧下降,甚至导致解释器崩溃,而线程池的最大线程数参数可以控制系统中并发线程的数量不超过此数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| import time
from concurrent.futures import ThreadPoolExecutor
def task(i):
print(f'任务{i}开始!')
time.sleep(i)
print(f'任务{i}结束!')
return i
start = time.time()
pool = ThreadPoolExecutor(3)
future01 = pool.submit(task, 1)
future02 = pool.submit(task, 2)
future03 = pool.submit(task, 3)
pool.shutdown()
print(f"程序耗时{time.time() - start}秒钟")
print("future01的结果", future01.result())
print("future02的结果", future02.result())
print("future03的结果", future03.result())
|
使用线程池来执行线程任务的步骤如下:
- 调用 ThreadPoolExecutor 类的构造器创建一个线程池。
- 定义一个普通函数作为线程任务。
- 调用 ThreadPoolExecutor 对象的 submit() 方法来提交线程任务。
- 当不想提交任何任务时,调用 ThreadPoolExecutor 对象的 shutdown() 方法来关闭线程池。
线程应用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| import requests
from lxml import etree
import os
import asyncio
import time
import threading
def get_img_urls():
res = requests.get("https://www.pkdoutu.com/photo/list/", headers={
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36"
})
selector = etree.HTML(res.text)
img_urls = selector.xpath('//li[@class="list-group-item"]/div/div/a/img[@data-backup]/@data-backup')
print(img_urls)
return img_urls
def save_img(url):
res = requests.get(url)
name = os.path.basename(url)
with open("imgs/" + name, "wb") as f:
f.write(res.content)
print(f"{name}下载完成!")
def main():
img_urls = get_img_urls()
[save_img(url) for url in img_urls]
t_list = []
for url in img_urls:
t = threading.Thread(target=save_img, args=(url,))
t.start()
t_list.append(t)
for t in t_list:
t.join()
if __name__ == '__main__':
start = time.time()
main()
end = time.time()
print(end - start)
|
针对IO密集型任务,Python多线程可以发挥出不错的并发作用
多进程
由于GIL的存在,python中的多线程其实并不是真正的多线程,如果想要充分地使用多核CPU的资源,在python中大部分情况需要使用多进程。
multiprocessing包是Python中的多进程管理包。与threading.Thread类似,它可以利用multiprocessing.Process对象来创建一个进程。该进程可以运行在Python程序内部编写的函数。该Process对象与Thread对象的用法相同,也有start(), run(), join()的方法。此外multiprocessing包中也有Lock/Event/Semaphore/Condition类 (这些对象可以像多线程那样,通过参数传递给各个进程),用以同步进程,其用法与threading包中的同名类一致。所以,multiprocessing的很大一部份与threading使用同一套API,只不过换到了多进程的情境。
python的进程调用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| import multiprocessing
import time
def foo():
print("foo start...")
time.sleep(5)
print("foo end...")
def bar():
print("bar start...")
time.sleep(3)
print("bar end...")
if __name__ == '__main__':
start = time.time()
t1 = multiprocessing.Process(target=foo, args=())
t1.start()
t2 = multiprocessing.Process(target=bar, args=())
t2.start()
t1.join()
t2.join()
end = time.time()
print(end - start)
|
协程
协程,又称微线程。英文名Coroutine。协程是一种用户态的轻量级线程。
协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈。因此:
协程能保留上一次调用时的状态(即所有局部状态的一个特定组合),每次过程序重新进入时,就相当于进入上一次调用的状态,换种说法:进入上一次离开时所处逻辑流的位置。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| def foo():
print("OK1")
yield 100
print("OK2")
yield 1000
def bar():
print("OK3")
yield 200
print("OK4")
yield 2000
gen = foo()
ret = next(gen)
print(ret)
gen2 = bar()
ret2 = next(gen2)
print(ret2)
ret = next(gen)
print(ret)
ret2 = next(gen2)
print(ret2)
|
asyncio即Asynchronous I/O是python一个用来处理并发(concurrent)事件的包,是很多python异步架构的基础,多用于处理高并发网络请求方面的问题。
为了简化并更好地标识异步IO,从Python 3.5开始引入了新的语法async和await,可以让coroutine的代码更简洁易读。
asyncio 被用作多个提供高性能 Python 异步框架的基础,包括网络和网站服务,数据库连接库,分布式任务队列等等。
asyncio 往往是构建 IO 密集型和高层级 结构化 网络代码的最佳选择。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| import asyncio
async def task(i):
print(f"task {i} start")
await asyncio.sleep(1)
print(f"task {i} end")
loop = asyncio.get_event_loop()
tasks = [task(1), task(2)]
loop.run_until_complete(asyncio.wait(tasks))
loop.close()
|
task: 任务,对协程对象的进一步封装,包含任务的各个状态;asyncio.Task是Future的一个子类,用于实现协作式多任务的库,且Task对象不能用户手动实例化,通过下面2个函数loop.create_task() 或 asyncio.ensure_future()创建。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| import asyncio, time
async def work(i, n):
print('任务{}等待: {}秒'.format(i, n))
await asyncio.sleep(n)
print('任务{}在{}秒后返回结束运行'.format(i, n))
return i + n
start_time = time.time()
tasks = [asyncio.ensure_future(work(1, 1)),
asyncio.ensure_future(work(2, 2)),
asyncio.ensure_future(work(3, 3))]
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
loop.close()
print('运行时间: ', time.time() - start_time)
for task in tasks:
print('任务执行结果: ', task.result())
|
3.8版本之后
async.run() 运行协程
async.create_task()创建task
async.gather()获取返回值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| import asyncio, time
async def work(i, n):
print('任务{}等待: {}秒'.format(i, n))
await asyncio.sleep(n)
print('任务{}在{}秒后返回结束运行'.format(i, n))
return i + n
tasks = []
async def main():
global tasks
tasks = [asyncio.create_task(work(1, 1)),
asyncio.create_task(work(2, 2)),
asyncio.create_task(work(3, 3))]
await asyncio.wait(tasks)
start_time = time.time()
asyncio.run(main())
print('运行时间: ', time.time() - start_time)
for task in tasks:
print('任务执行结果: ', task.result())
|
asyncio.create_task() 函数在 Python 3.7 中被加入。
asyncio.gather方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
import asyncio, time
async def work(i, n):
print('任务{}等待: {}秒'.format(i, n))
await asyncio.sleep(n)
print('任务{}在{}秒后返回结束运行'.format(i, n))
return i + n
async def main():
tasks = [asyncio.create_task(work(1, 1)),
asyncio.create_task(work(2, 2)),
asyncio.create_task(work(3, 3))]
response = await asyncio.gather(tasks[0], tasks[1], tasks[2])
print("异步任务结果:", response)
start_time = time.time()
asyncio.run(main())
print('运行时间: ', time.time() - start_time)
|
aiohttp
爬虫的requests模块,它是阻塞式的发起请求,每次请求发起后需阻塞等待其返回响应,不能做其他的事情。aiohttp模块可以理解成是和requests对应Python异步网络请求库,它是基于 asyncio 的异步模块,可用于实现异步爬虫,有点就是更快于 requests 的同步爬虫。
aiohttp是一个为Python提供异步HTTP 客户端/服务端编程,基于asyncio的异步库。asyncio可以实现单线程并发IO操作,其实现了TCP、UDP、SSL等协议,aiohttp就是基于asyncio实现的http框架。
1
2
3
4
5
6
7
8
9
| import aiohttp
import asyncio
async def main():
async with aiohttp.ClientSession() as session:
async with session.get("http://httpbin.org/headers") as response:
print(await response.text())
asyncio.run(main())
|
